What Happened the Day After
In my previous post I described how I stopped everything to build the Operating System of an AI-First company — Claude.md, Memory, Skills, and Hooks. I promised that in the next post we'd get back to code. So here we are. And the timing couldn't be better.
This very week Anthropic launched a new feature — Code Review in Claude Code. A Multi-Agent system that runs automatically on every PR, hunts for bugs, filters out False Positives, and ranks findings by severity. What makes this interesting is that I had just built exactly that — in two different ways — during my experiment over the past two weeks.
So I now have three approaches to AI Code Review, all running on the same BridgeBoard codebase. And comparing them is exactly what anyone managing a dev team or building a company needs in order to decide what works for them.
The Problem: Who Reviews the Code When Everyone Is Writing Faster?
This point matters before we dive into the approaches themselves.
When I was working with Agent Teams in the early days of the experiment — a Backend, Frontend, and Tests team that built BridgeBoard — they produced code fast. Very fast. A complete project with an API, database, user interface, and tests in a single day.
But who reviews all of that?
At the companies I've worked at, Code Review was already a bottleneck before the AI era. Experienced engineers burning hours on reviews, PRs stuck in a queue, and in the end — once the queue got too long — someone would skim and hit Approve just to keep things moving. Now multiply the volume of code by 2–3x thanks to AI and you get the real problem.
Anthropic themselves say that the amount of code each of their engineers produces has gone up 200% over the past year. And these are engineers who are individually very high-caliber. So imagine an average company.
I went to find out: what are the options available today, and which one fits whom?
Approach 1: Sub-Agents — A Team of Specialists You Build Yourself
What Is It?
Four specialized Agents, each an expert in a different domain, running in parallel across the entire codebase and generating a detailed findings report. I asked Claude Code to build a team of Reviewers:
- Security Reviewer — scans for security vulnerabilities, data exposure, injections
- Performance Reviewer — looks for N+1 Queries, missing indexes, unnecessary computations
- Test Coverage Reviewer — analyzes coverage gaps, broken tests, missing Edge Cases
- Code Quality Reviewer — checks for duplication, Type Safety, dead code, style


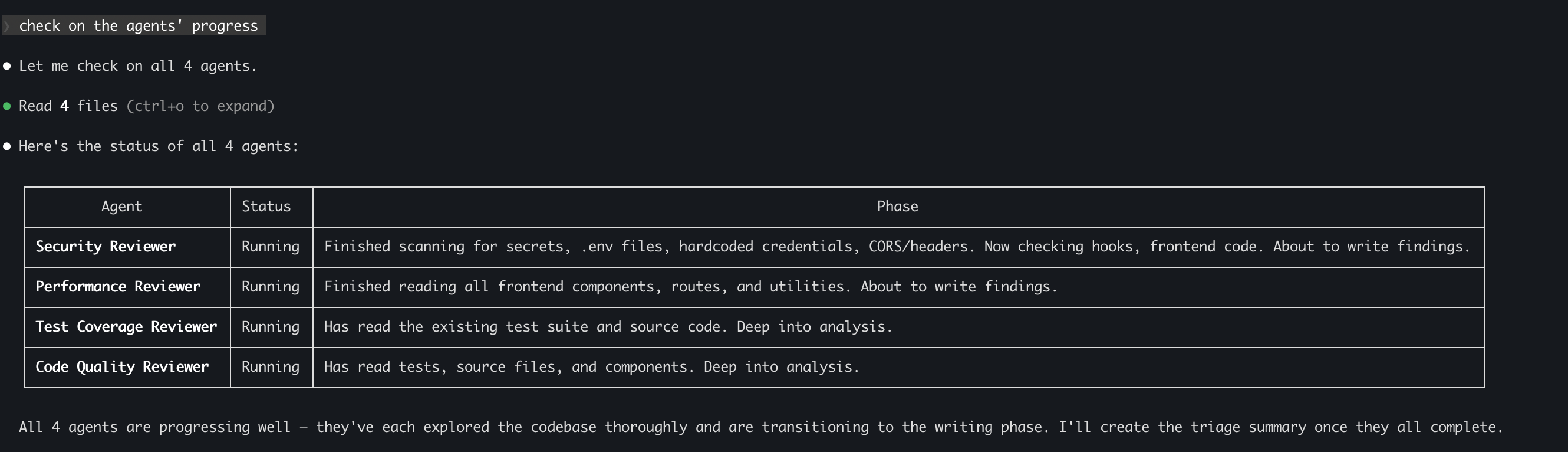
Why Sub-Agents and Not Agent Teams?
Good question — because in the early days of the experiment I successfully used Agent Teams to build the product. But there's a meaningful difference.
Agent Teams excel when you need to produce code that fits together. The Backend, Frontend, and Tests agents worked on the same codebase, coordinated through the orchestrator, and resolved conflicts. That's a collaborative production scenario.
Sub-Agents are a better fit for review because each Reviewer does an independent, read-only analysis of the same code. The Security Agent doesn't need to know what the Performance Agent found. No conflicts, no dependencies. And when each one receives only the context it needs — its instructions plus the relevant code files — that saves a huge number of tokens compared to a full team session.
There's another critical advantage: Triage. The findings come back to me raw and unfiltered. I decide what matters and what doesn't. With an Agent Team, the team tries to resolve things internally — and that's exactly what I don't want during a review phase. I want to see everything and then apply human judgment.
The pattern I arrived at: Agent Teams for building (collaborative output) → Sub-Agents for review (independent analysis) → Human for Triage (judgment) → Agent Teams again for fixes (based on Triage decisions).
What Did They Find?
Here's the summary:
| Agent | Findings | CRITICAL | HIGH | MEDIUM | LOW |
|---|---|---|---|---|---|
| Security | 14 | 1 | 5 | 5 | 3 |
| Performance | 14 | 1 | 4 | 6 | 2 |
| Code Quality | 18 | — | 1 | 8 | 9 |
| Test Coverage | 22 | 3 | 7 | 8 | 3 |
| Total (Raw) | 68 | 5 | 17 | 27 | 17 |
After deduplication (findings raised by multiple Agents): 62 unique findings.
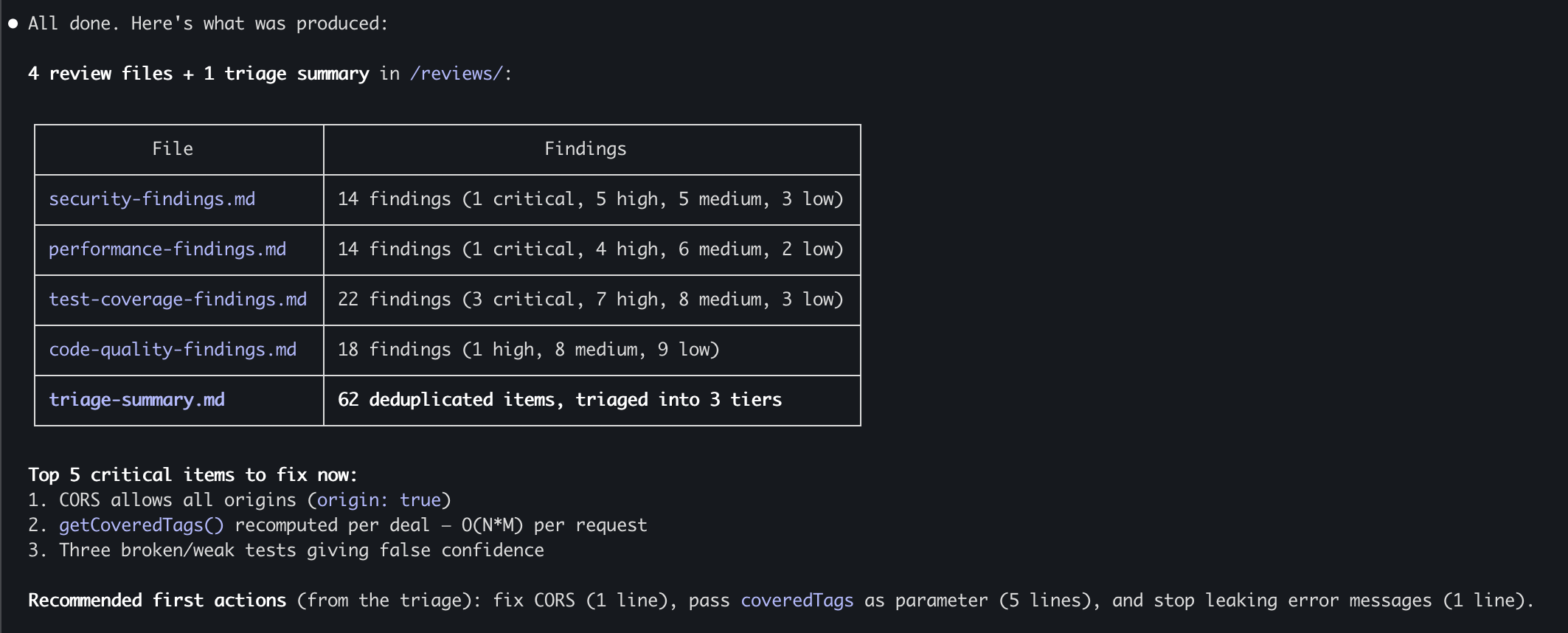
A few examples that illustrate the value:
Security Agent found that CORS was allowing any origin — meaning any website could read data from the API. In production that's a critical vulnerability. Also: database credentials hardcoded directly in the code, an error handler leaking internal error messages to the client, no Rate Limiting, no Security Headers.

Performance Agent found that getCoveredTags() was being recomputed for every Deal — an O(N*M) algorithm on every request. A 5-line fix. Also: the Dashboard was being fetched twice (two identical HTTP requests), no Pagination on any Endpoint, no Pool Config for the Database.

Test Coverage Agent was perhaps the most surprising. It found three CRITICAL tests that, despite passing, weren't actually testing what they claimed to. One test was checking the opposite of what its name said. Another accepted any valid value as an assertion and therefore always passed. That's false confidence that can cost you dearly.
Something Interesting That Happened: Cross-Agent Overlap
Three findings were independently raised by multiple Agents:
getCoveredTags()O(N*M) — surfaced by Performance, Quality, and Coverage- Double Dashboard Fetch — surfaced by Performance and Quality
- Logger disabled but still called in code — surfaced by Security and Quality
That's an interesting data point. When multiple "experts" identify the same problem from different angles, it's a strong signal that it genuinely matters. It also validates the quality of the findings.
The Triage — Where Human In The Loop Comes In
After all the findings came in, I sat down with Claude and did a joint review. I didn't fix everything — that's the point.
In a real company there's no time to fix 62 findings. So we went through the list, I marked what was critical to fix immediately and what went into the backlog. Everything was documented in a Markdown file — the kind you can then push to Jira via MCP or any other task management tool.
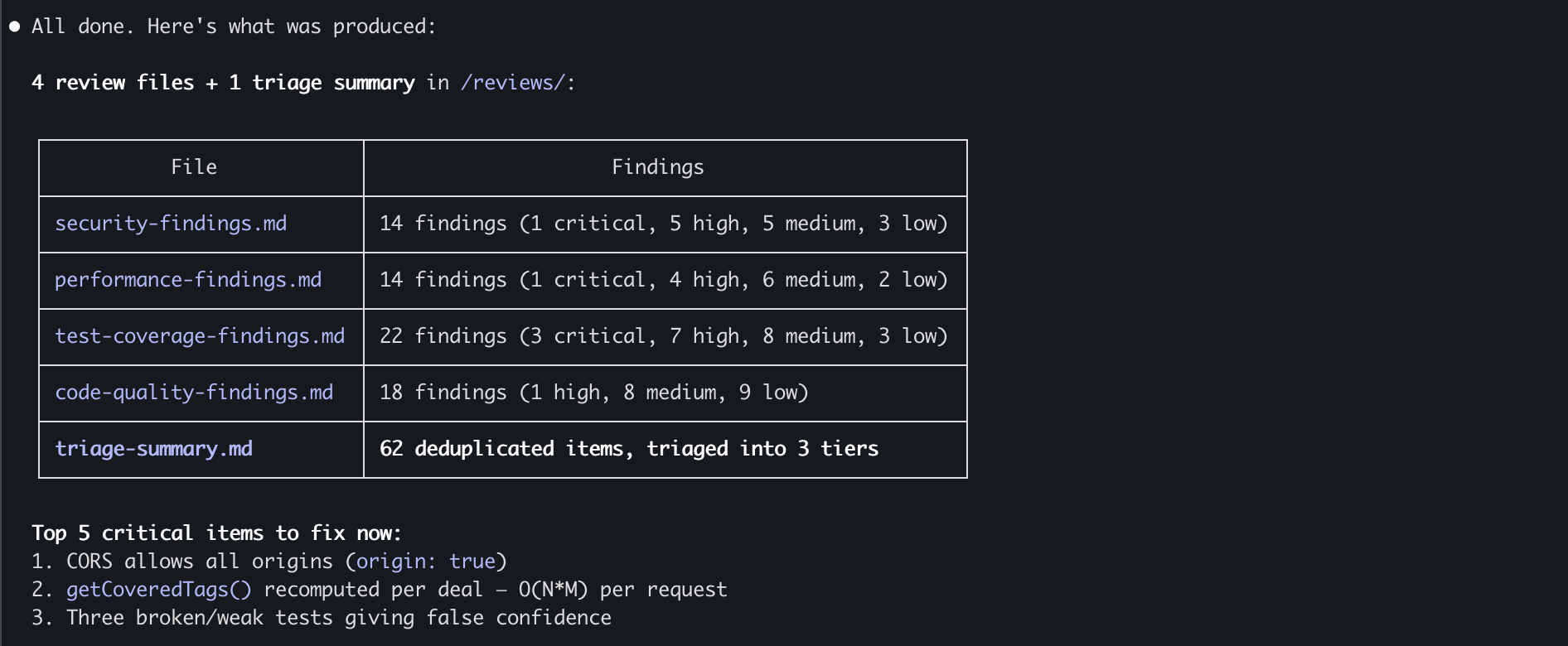
The five fixes with the best Impact-to-Effort ratio:
- Passing
coveredTagsas a parameter — eliminates O(N*M) per-request (5 lines) - Single Dashboard fetch — eliminates 50% of HTTP traffic (10 lines)
- Setting
staleTimein QueryClient — eliminates unnecessary Refetch (1 line) - Fixing CORS to an Allowlist — closes a critical vulnerability (1 line)
- Stopping Error Message leakage — stops exposing internal data (1 line)
18 lines of code that close the most critical issues.
Run Metrics
| Metric | Value |
|---|---|
| Total time | ~15–30 minutes |
| Tokens (estimate) | ~215K |
| Cost (estimate) | $5–10 |
| Pattern | 4 Agents in parallel + Triage |
| Output | 54 passing tests, prioritized backlog of 62 findings |
Approach 2: AI Code Review in GitHub Actions — Automation on Every PR
What Is It?
Two GitHub Actions I created that run automatically on every Pull Request:
- AI PR Description Generator — produces a structured, detailed description for every PR
- AI Code Reviewer — goes through the Diff and leaves comments on issues
Both Actions call the Anthropic API directly, send the Diff, and publish the results as Comments on the PR.
How Did I Build It?
Pretty straightforward with Claude Code. Two YAML files in .github/workflows/. One triggers an API call with the PR Diff when a PR is opened and publishes a summary. The other does the same with a focus on Code Review — checking Security, Performance, Error Handling, missing tests, and readability issues.
Time to build everything: about half an hour. Including edits and fixes until everything ran. Yes, half an hour.
The cost: a few dollars on the Anthropic API, which I added as a Secret in GitHub. On each run the Action sends the Diff (up to 8–10K characters) to Claude Sonnet with clear instructions — and the response comes back as a Comment.
What Did It Find?
I ran it against several different PRs. Here are two examples:
A UX improvements PR — a Designer Agent and Developer Agent team improved the UI that had been intentionally left basic. The AI Code Review found:
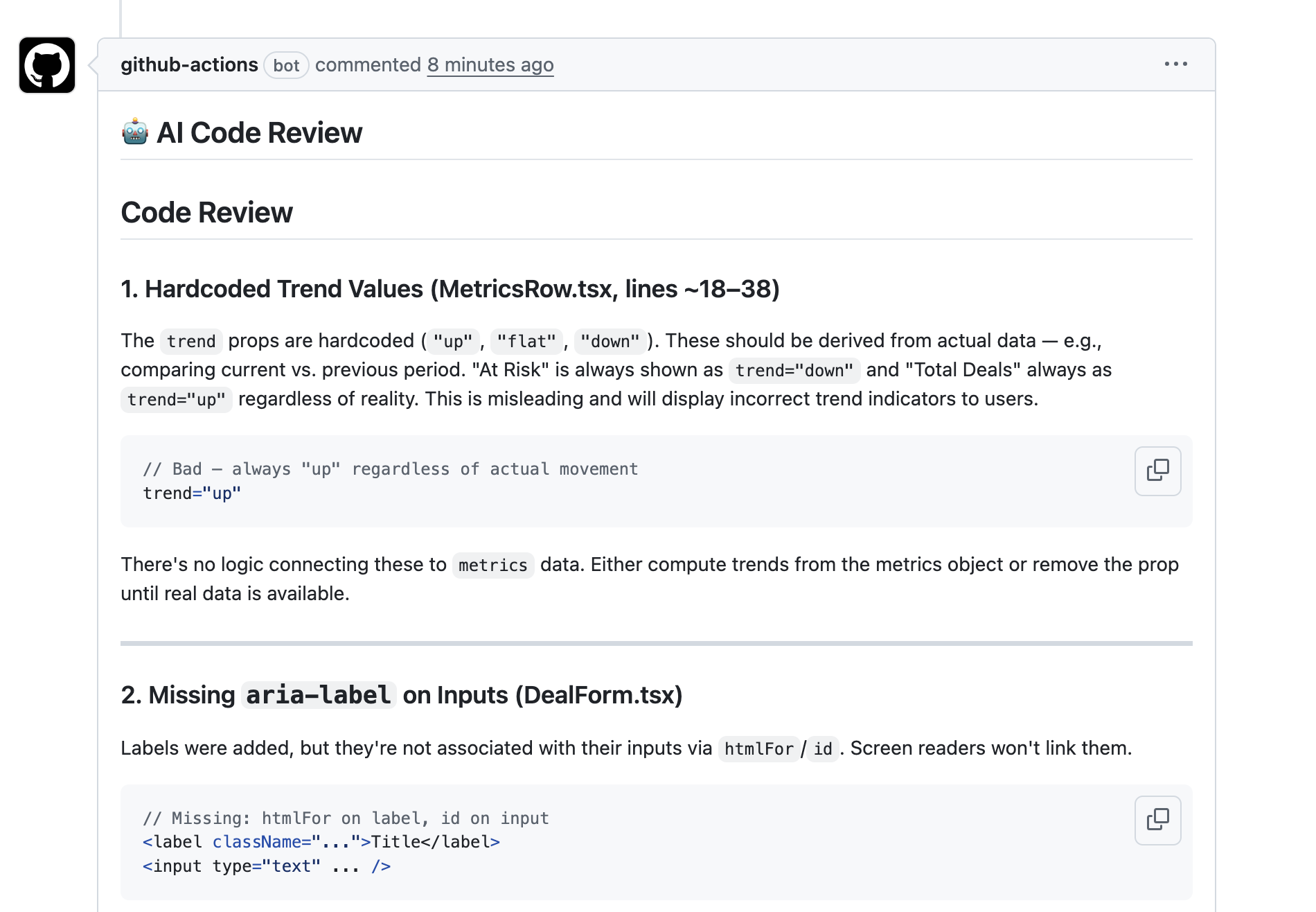
- Hardcoded Trend Values — Trend values like "up", "flat", "down" written hard-coded instead of being derived from the data. The "At Risk" metric always shows a downward trend and "Total Deals" always shows an upward trend — regardless of reality. This misleads users.
- Missing
aria-labelon Inputs — Labels not connected to Inputs viahtmlFor/id. Screen readers won't associate them. Accessibility issue.
An AI-First infrastructure PR — adding Claude.md, Skills, Hooks, and Settings. The AI Code Review found:
- Timer/Resource Leaks — in Test Utilities,
setTimeoutkeeps running even after the Promise has already resolved. Wasted resources and a problem in test environments that use Fake Timers. - Predicate Exceptions not handled — if a Predicate function throws, it doesn't become a Rejected Promise but rather an unhandled error. The Promise gets stuck until Timeout.
waitForEventcaptures old events — there's no concept of "events from this point forward." If a matching event already exists in memory, it returns it immediately — even if it's not relevant. A bug that can mask real problems.
In both cases — useful comments that save the human reviewer time. The infrastructure PR was very large (over 15,000 lines changed, 144 files) and the review still surfaced specific and relevant findings.
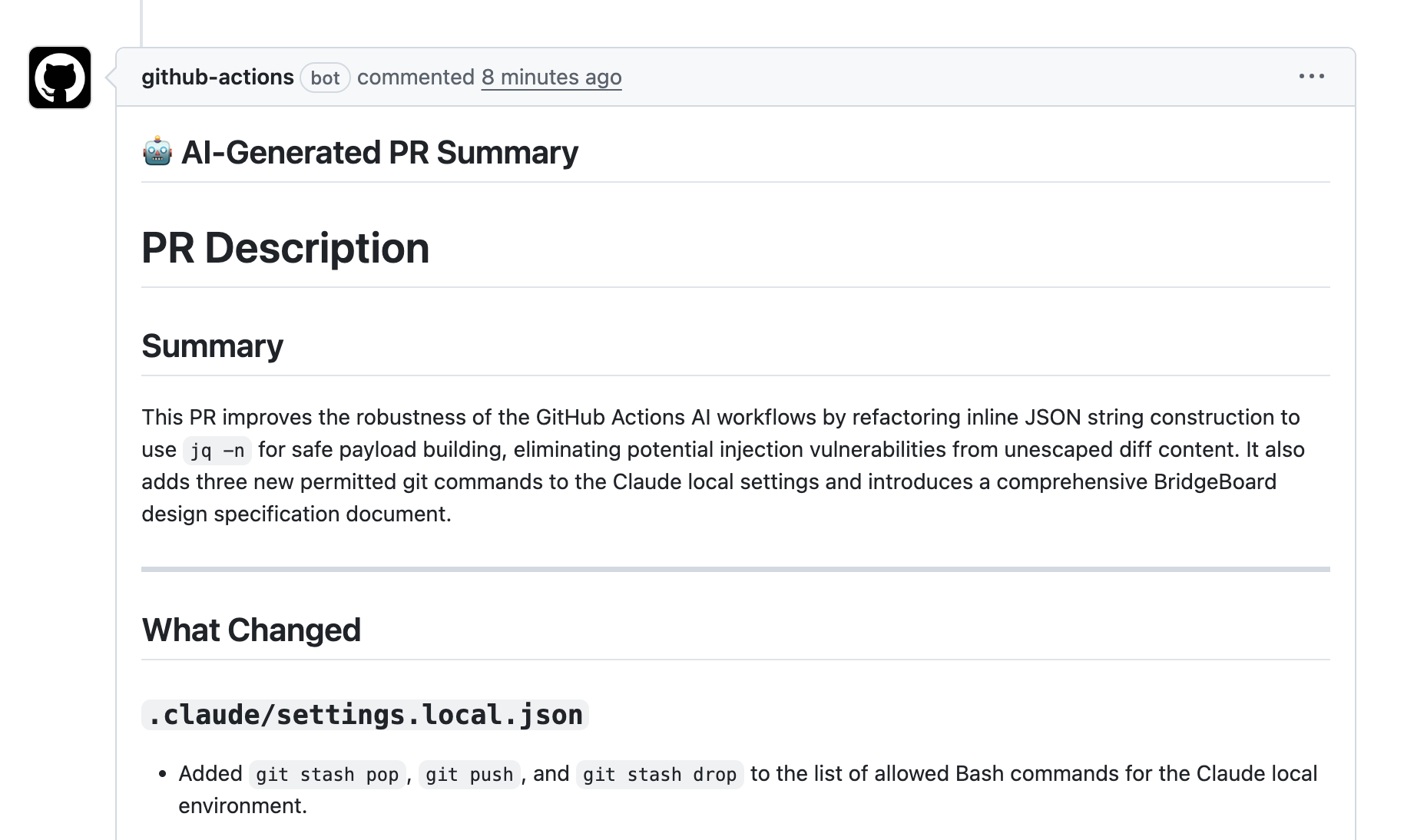
In addition, the PR Description Generator produced a complete description — a 2–3 sentence summary, a breakdown of changes by area, why it matters, notes for tests, and known risks (including a note that the Diff was truncated and some content may be missing). Something most developers skip entirely.
The Human In The Loop Here
After reading the AI Code Review findings, I consulted with Claude and we chose not to fix everything. Because not everything is critical — and that's something I can say as a person who writes code himself and doesn't treat what the AI says as gospel.
I also manually spot-checked parts of the code and found a few comments I would have asked to fix. To me that's perfectly fine and part of the deal. But I spent less time going over the code and felt more confident — mostly because I knew what it had looked at and commented on.
And that's different from the Sub-Agents approach. There the review goes deeper, covers the entire codebase, and produces a comprehensive report. Here it's lighter, faster, and runs automatically on every PR — small and large alike.
What Could Be Improved?
- The Review Prompt isn't perfect. You constantly need to think about how to refine it — adding, updating, or removing unwanted behaviors. Exactly like onboarding a new engineer who's learning the team's standards.
- You could separate the Review by type of change — Backend vs. Frontend, small Hotfix vs. large feature, script changes vs. building a new Service. Each type warrants different comments and checks different things. That also saves tokens.
- It might be worth adding a Hook that runs before the Commit so some findings never even reach the PR. You need to find the right balance between what runs locally on the developer's machine and what runs in CI where everyone can see it.
Approach 3: Anthropic Code Review — The Managed Solution
What Is It?
Anthropic launched Code Review directly in Claude Code this week. Unlike the two previous approaches — here you build nothing. An Admin enables the feature at the organization level, connects it to GitHub, and it runs.
When a PR is opened, the system dispatches a team of Agents that work in parallel — some look for bugs, others validate the findings to filter out False Positives, and finally a last Agent ranks everything by severity. The output: a single, clean Comment on the PR with a general overview and Inline Comments on specific lines.
I can't run this myself — the feature is only available to Teams and Enterprise customers. So I'm working from the data Anthropic published, which I think is interesting enough to compare.
What Does the Data Show?
Anthropic runs this on almost every internal PR. Before the feature, 16% of PRs received meaningful comments. After — 54%. That's 3.4x more PRs getting a real Review rather than a quick skim.
For large PRs (over 1,000 lines changed) — 84% received findings, with an average of 7.5 findings per PR. For small PRs (fewer than 50 lines) — 31% received findings, with an average of 0.5. That's logical — a large PR hides more problems.
A stat that caught my attention: Anthropic engineers disputed fewer than 1% of findings. Meaning the Verification and Ranking work well enough that there are almost no False Positives.
They also give specific examples: in one case, a single-line change — the kind that would normally get an immediate Approve in a regular Review — would have broken the Authentication mechanism of a Production service. The Agent Review caught it before the Merge.
Cost
$15–25 per Review on average, depending on size and complexity. Calculated based on Token Usage. That's already a number worth seriously considering in the context of ROI.
The Comparison: Three Approaches, Three Levels of Maturity
After running the first two and studying the data on the third, I see this as a maturity model — not a competition of "which is better":
Cost Per Review
Sub-Agents: $5–10 per full run across the entire codebase. But it's a comprehensive review, not per-PR. Worth running once a sprint or before a major release.
AI CR (GitHub Actions): Pennies per PR. Sends a bounded Diff to the API and gets a response. Cost is nearly zero.
Anthropic Code Review: $15–25 per PR. A team of 8 engineers with 4 PRs per day for the team = $1,300–2,200 per month. Not trivial, but also not much if you consider how much Senior Engineer time it saves.
Who Needs to Build It?
Sub-Agents: An engineer needs to build the Prompt, configure the Agents, and maintain it. It took me a few hours including Triage. For a team unfamiliar with Claude Code — maybe half a day.
AI CR (GitHub Actions): An engineer builds it once (half an hour), then it runs on its own. Ongoing maintenance: updating Prompts when you discover misses or misidentifications.
Anthropic Code Review: Admin clicks a button. Zero build, zero maintenance. Anthropic maintains the Model, Agents, and Prompts.
When in the SDLC?
Sub-Agents: Before the PR. During development or before a release. Deep review of the entire codebase.
AI CR (GitHub Actions): The moment a PR is opened. Automatic review that gives an initial signal within seconds.
Anthropic Code Review: Also the moment a PR is opened, but a deeper review that takes ~20 minutes. Multi-Agent analysis.
Depth of Findings
Sub-Agents: Deepest. 68 findings including 5 CRITICAL. Reviews the entire codebase, not just the Diff. Found structural issues like the O(N*M) Algorithm, tests that always pass but test nothing, and architectural problems.
AI CR (GitHub Actions): Less deep but focused. Reviews only the Diff, capped at 8–10K characters. Found good issues (Hardcoded Values, Accessibility, Resource Leaks) but not at the level of a full review.
Anthropic Code Review: Per the data — significant depth. Findings in 84% of large PRs. Multi-Agent Verification reduces False Positives to under 1%. Reviews the context around the Diff — tests, Config, neighboring modules.
An Important Point: They Complement, Not Compete
You can combine them:
- Sub-Agents once per sprint or before a release
- AI CR on every PR (cheap and fast)
- Anthropic Code Review on critical or large PRs
It's exactly like how a real company has multiple layers: Linter runs locally, CI/CD checks tests, and a Human Reviewer goes over the logic. Except now the review layers themselves are getting an upgrade too.
The ROI: Let's Talk Numbers
Take a sample team: 8 engineers, an average of 4 PRs per day for the team, and each PR Review currently takes 45 minutes of a Senior Engineer's time at ~$80/hour.
The situation today (without AI):
- 4 PRs × 45 minutes = 3 hours of Review per day
- 3 hours × 22 working days = 66 hours per month
- 66 × $80 = ~$5,280 per month on Code Review
- In practice: some PRs get a skim, not a real review
With AI CR (GitHub Actions):
- Cost: ~$5–10 per month (pennies per PR)
- Human review time drops to ~20 minutes (since the basics are already checked)
- Savings: ~30 hours per month = ~$2,400 per month
- Plus: 100% of PRs get a review, not just the ones someone got to
With Anthropic Code Review:
- Cost: $15–25 × 88 PRs = $1,300–2,200 per month
- Human review time drops to ~15 minutes (findings already verified and ranked)
- Savings: ~40 hours per month = ~$3,200 per month
- Plus: higher-quality findings, fewer False Positives
With Sub-Agents (once a week/sprint):
- Cost: ~$10–20 per sprint = ~$40–80 per month
- Value: catches structural problems that aren't tied to a specific PR
- This doesn't replace ongoing CR, it complements it
These are estimates, not exact numbers. But the direction is clear: even the simplest AI CR that costs almost nothing already saves thousands of dollars a month and raises quality. And that's before you factor in bugs caught early that never make it to production — where the cost of fixing them is much higher.
A Note on Other Tools in the Market
I want to note that there's a whole ecosystem of AI Code Review tools today — Baz, Qodo (formerly CodiumAI), and others. In this experiment I deliberately chose to build it myself in order to understand the mechanics from the inside — what works, what doesn't, and where the challenges are. In a future post I plan to compare the managed tools to help anyone who prefers an out-of-the-box solution.
Bottom Lines
1. Code Review Is the First Place Where "Build vs Buy" in AI Becomes a Real Business Decision
This isn't a philosophical debate. There are clear costs, measurable savings, and results you can see from day one. If you manage a team and aren't using any AI tool for Code Review — you're paying more and getting less.
2. The Right Approach Depends on Where You Are
Independent builder or small startup? Start with a simple GitHub Action — half an hour to set up, nearly free, and you get an immediate signal. Mid-size team? Add Sub-Agents once a sprint. Enterprise? Anthropic's Managed Solution (or another managed tool) is probably worth the money — zero maintenance and deep analysis.
3. AI Doesn't Replace the Reviewer — It Changes What the Reviewer Does
The early-cycle Security, Performance, and style issues? AI handled those. The human Reviewer can now focus on what truly requires judgment: architecture, Business Logic, UX, and trade-offs that only someone who knows the product and the customers can evaluate.
At the companies I've worked at, there were dedicated Security and Performance teams doing these reviews. Now, even a single developer with Sub-Agents can get 60% of the value those teams provided — freeing them to focus on what genuinely requires expertise. Multiply that across a company with dozens or hundreds of engineers and you start to see the Compound Effect.
4. The Expensive Thing Is Not the Tool — It's Using Nothing at All
A team producing 3x more code with AI and running it all through manual-only Review is sitting on a problem that will only grow. Every week that passes without any AI Code Review in the workflow is a week of bugs that could have been caught, review hours that could have been saved, and experienced engineers burning time on things a machine does better.
What's Next?
In the next post I'm leaving the SDLC for a moment and moving into territory that really interests me: non-Engineering Use Cases. What happens when a Product Manager, Support, Sales, or Designer tries to work with AI without an engineer to help? What's blocking them? And where can we open up that bottleneck?
This post is part of the AI-First Company experiment series I'm running and documenting as I go. Follow me here and at chenfeldman.io for the full picture.
Previous post: I Stopped Everything to Build the AI-First Company Operating System
First post: I Built a Simulated AI-First Company in One Day
This post was written by me and Claude together, based on the findings, data, and experience I gathered working with these tools. If you spot a mistake, inaccuracy, or something worth changing — I'd love to hear it.